
Abstract
The attention mechanism has revolutionized natural language processing, becoming a cornerstone of modern AI systems. This article will provide a detailed explanation of how attention mechanisms work in modern language models and their impact on performance, while citing the paper "Attention is All You Need" by Vaswani et al. (2017).
Introduction
The attention mechanism has revolutionized natural language processing,
becoming a cornerstone of modern AI systems. First of all, let's define what attention is.
For a human, attention is the process of focusing on a specific task or object. For example,
when
we work on that leetcode problem, we focus on the problem statement and the solution. But, how
do we translate this concept to a machine?
For a machine, attention is the process of focusing on a specific part of the input.
For example, when we train a machine learning model, we want to focus on the most important
features
of the input.
Example: Translation Attention
Consider the Spanish sentence: "El gato negro duerme en el jardín"
When translating to English "The black cat sleeps in the garden", the attention mechanism works like this:
- For translating "black cat", the model pays high attention to "gato negro"
- For "sleeps", attention focuses strongly on "duerme"
- For "in the garden", attention concentrates on "en el jardín"
The attention mechanism allows the model to dynamically focus on relevant parts of the input sentence while generating each word of the translation, rather than trying to remember the entire sentence at once.
What is Attention?
Let's add some math to the mix.
Mathematical Definition
Attention can be expressed as a mathematical function:
Attention(Q, K, V) = softmax(QKT)V
- Q (Query): What we're looking for
- K (Key): What we're comparing against
- V (Value): The actual information we want to extract
This formula allows the model to compute relevance scores between elements and create weighted combinations of values based on those scores.
What does this mean? First of all, we have a query, which is the input we want to translate. We also have a key, which is the input we want to compare against. Finally, we have a value, which is the actual information we want to extract. This is the key idea behind attention mechanisms. Now, let's see how it works."An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key."
How it works
The attention mechanism works by computing the similarity between the query and the key, and then using the softmax function to normalize the results. The softmax function is a function that takes a vector and returns a vector of the same length, where each element is the softmax of the corresponding element in the input vector.
Multi-Head Attention
Instead of performing attention once, the transformer uses multiple attention heads in parallel. This is called multi-head attention.
Multi-Head Attention Explained
Multi-head attention allows the model to:
- Focus on different parts of the input sequence simultaneously
- Capture different types of relationships between words
- Learn multiple representation subspaces
For example, one attention head might focus on syntactic relationships, while another focuses on semantic relationships.
Mathematical View
For each head i:
headi = Attention(QWiQ, KWiK, VWiV)
The final output is a concatenation of all heads, projected through a linear layer:
MultiHead(Q,K,V) = Concat(head1,...,headh)WO
Attention Example: Understanding Complex Phrases
Let's analyze how attention might work on the phrase: "A fire-breathing dragon lives in my garage"
When processing this sentence, different attention heads might focus on different aspects:
- Head 1 (Subject-Verb Relations):
- When processing "lives", pays high attention to "dragon" (who is doing the living?)
- Lower attention to other words like "fire-breathing" or "garage"
- Head 2 (Descriptive Relations):
- When looking at "dragon", pays high attention to "fire-breathing" (what kind of dragon?)
- Creates connections between the subject and its attributes
- Head 3 (Location Relations):
- Focuses on "lives in" and "garage" (where is the dragon?)
- Establishes spatial relationships in the sentence
The attention scores might look something like this:
Word | Main words it attends to ----------------|------------------------ fire-breathing → dragon (0.8), lives (0.1) dragon → lives (0.6), fire-breathing (0.3) lives → dragon (0.7), garage (0.2) garage → lives (0.4), in (0.4)
These multiple attention heads working in parallel allow the model to understand:
- The main subject (dragon) and its action (lives)
- The subject's characteristics (fire-breathing)
- The location (garage) and how it relates to the subject
Cross-Attention
The cross-attention mechanism is used in the decoder to attend to the encoder's output. This is the case of the transformer, which takes the input and outputs the final result.
Understanding Cross-Attention
Cross-attention is a crucial mechanism that allows the decoder to access information from the encoder. Here's how it works:
- Query-Key-Value Interaction:
- Queries (Q) come from the decoder's previous layer
- Keys (K) and Values (V) come from the encoder's output
- This allows the decoder to "look back" at the source sequence while generating output
- Information Flow:
- The decoder can access any part of the input sequence at any time
- This creates a direct path between input and output, helping with long-range dependencies
Example: Translation with Cross-Attention
Consider translating: "The red car" → "La voiture rouge"
When generating... | Strongly attends to... -------------------|-------------------- "La" → "The" (article) "voiture" → "car" (noun) "rouge" → "red" (adjective)
Key Benefits of Cross-Attention:
- Enables precise word-by-word translation
- Handles word order differences between languages
- Maintains context throughout the translation process
- Allows flexible attention patterns based on the current generation needs
The Transformer
Visual Representation
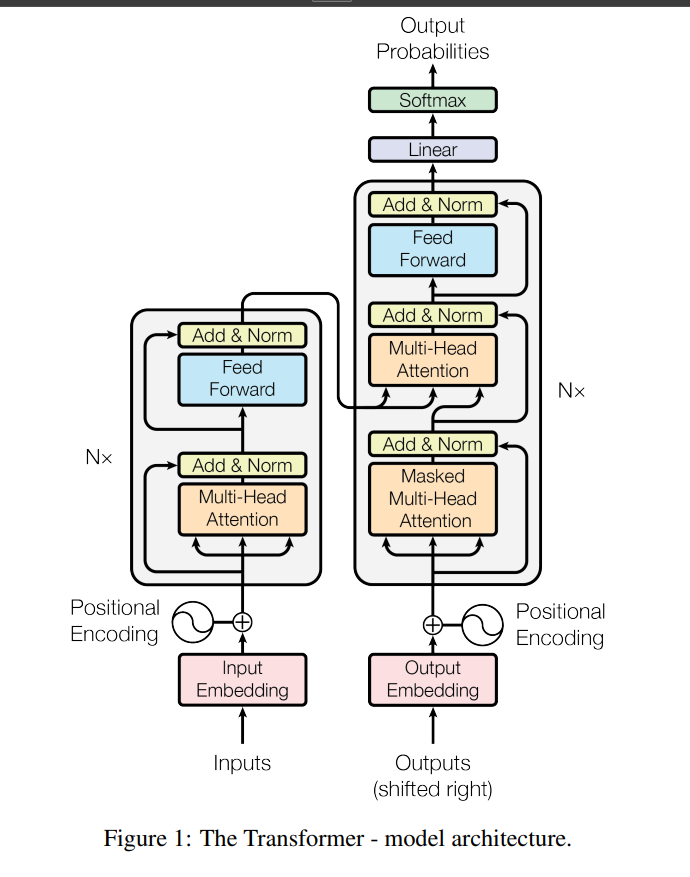
What is a seq2seq model?
A seq2seq model is a model that takes a sequence as input and outputs a sequence. This is the case of the transformer, which takes a sequence of words as input and outputs a sequence of words.
Seq2Seq Example: Language Translation
Consider translating an English sentence to French:
- Input sequence: "How are you?"
- Output sequence: "Comment allez-vous?"
The model processes the input sequence word by word:
- Reads "How" → Processes
- Reads "are" → Processes
- Reads "you?" → Processes
Then generates the output sequence word by word:
- Outputs "Comment"
- Outputs "allez"
- Outputs "vous?"
This is a simplified example. In practice, the model handles more complex sentence structures and maintains context throughout the sequence.
From the Paper: Architecture Details
On the Encoder:
"The encoder is composed of a stack of N = 6 identical layers. Each layer has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position- wise fully connected feed-forward network. We employ a residual connection around each of the two sub-layers, followed by layer normalization. That is, the output of each sub-layer is LayerNorm(x + Sublayer(x)), where Sublayer(x) is the function implemented by the sub-layer itself. To facilitate these residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension dmodel = 512."
On the Decoder:
"The decoder is also composed of a stack of N = 6 identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to the encoder, we employ residual connections around each of the sub-layers, followed by layer normalization. We also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i."
How is it different from traditional RNNs?
The transformer is different from traditional RNNs because it uses the attention mechanism to process sequences. The attention mechanism allows the model to focus on the most important parts of the input, which is not the case of traditional RNNs, where the model processes the input sequence step by step.
Google's paper also mentions that the transformer is faster than the traditional RNNs, but it is not as good at capturing long-term dependencies.From the Paper: Computational Complexity
"As noted in Table 1, a self-attention layer connects all positions with a constant number of sequentially executed operations, whereas a recurrent layer requires O(n) sequential operations. In terms of computational complexity, self-attention layers are faster than recurrent layers when the sequence length n is smaller than the representation dimensionality d, which is most often the case with sentence representations used by state-of-the-art models in machine translations, such as word-piece [31] and byte-pair [25] representations. To improve computational performance for tasks involving very long sequences, self-attention could be restricted to considering only a neighborhood of size r in the input sequence centered around the respective output position. This would increase the maximum path length to O(n/r). We plan to investigate this approach further in future work."
Feed-Forward Network
The feed-forward network is a network that takes the input and outputs the final result. Let's see what the paper says about it:
From the Paper: Feed-Forward Network
"In addition to attention sub-layers, each of the layers in our encoder and decoder contains a fully connected feed-forward network, which is applied to each position separately and identically. This consists of two linear transformations with a ReLU activation in between. FFN(x) = max(0, xW1 + b1)W2 + b2 (2) While the linear transformations are the same across different positions, they use different parameters from layer to layer. Another way of describing this is as two convolutions with kernel size 1. The dimensionality of input and output is dmodel = 512, and the inner-layer has dimensionality df f = 2048."
Let's break down what feed-forward networks are and why they're important in the transformer architecture:
- Position-wise Processing: The feed-forward network processes each position in the sequence independently. This means if you have a sequence of 10 words, the same feed-forward network is applied to each word's representation separately.
- Two Linear Transformations: As mentioned in the paper, it consists of two linear
layers with a ReLU activation function between them. This can be thought of as:
- First transformation: Takes the 512-dimensional input and projects it to 2048 dimensions
- ReLU activation: Introduces non-linearity by setting negative values to zero
- Second transformation: Projects back from 2048 dimensions to 512 dimensions
- Purpose: The feed-forward network adds another level of abstraction to the model. While the attention mechanism captures relationships between different positions in the sequence, the feed-forward network allows the model to process this information further and learn more complex patterns.
Think of it as giving each position in the sequence a chance to "think deeply" about the information it has gathered through attention, before passing it on to the next layer. The increased dimensionality in the hidden layer (2048 vs 512) gives the network more capacity to learn complex patterns.
Layer Normalization
Layer normalization is a technique used to stabilize the learning process in deep neural networks. It normalizes the input to each layer, which helps with faster convergence and better performance.
From the Paper: Layer Normalization
"We employ a residual connection around each of the sub-layers, followed by layer normalization. That is, the output of each sub-layer is LayerNorm(x + Sublayer(x)), where Sublayer(x) is the function implemented by the sub-layer itself."
Let's break down how layer normalization works and why it's crucial in transformers:
- What it Does: Layer normalization computes the mean and variance across the features of each individual example in a batch, and uses these statistics to normalize the features.
- Key Components:
- Normalization: Subtracts the mean and divides by the standard deviation
- Learnable Parameters: Scale (γ) and shift (β) parameters that allow the network to undo the normalization if needed
- Applied After Each Sub-layer: Used after both self-attention and feed-forward networks
- Benefits:
- Stabilizes Training: Helps prevent the vanishing/exploding gradient problem
- Reduces Training Time: Allows for higher learning rates and faster convergence
- Independence: Each example is normalized independently, making it suitable for variable-length sequences
The combination of residual connections and layer normalization is crucial for training deep transformer networks effectively. It helps maintain stable gradients throughout the network and enables the model to learn more effectively.
Concluding
The transformer has had a huge impact on the field of natural language processing. It has revolutionized the way we understand language and it has opened the door to a whole new set of applications. This is the case of the GPT-3 model, which is a transformer-based model that has revolutionized the field of natural language processing.
ChatGPT 3
"ChatGPT 3 is a transformer-based model that has revolutionized the field of natural language processing. It is a model that can generate human-like text, and it has been used to create a whole new set of applications. It's name comes from Generative Pre-trained Transformer 3, which is the name of the model."
Key Takeaways
The Transformer architecture represents a pivotal moment in deep learning, introducing several groundbreaking concepts that have become fundamental to modern NLP. The self-attention mechanism allows models to dynamically focus on relevant parts of the input, breaking free from the sequential limitations of RNNs. Multi-head attention takes this further by enabling parallel processing of information from different representation subspaces.
The architecture's strength lies in its carefully designed components working in harmony: positional encodings preserve sequential information, layer normalization and residual connections ensure stable training, and the feed-forward networks add crucial non-linear processing capability. This elegant combination has proven so effective that it has spawned numerous variants and applications beyond just NLP, influencing fields from computer vision to biological sequence analysis.
Perhaps most importantly, the Transformer has shown us that with the right architectural choices, we can build models that not only process information efficiently but also learn to understand context and relationships in ways that more closely mirror human-like comprehension. This breakthrough has set the stage for the current era of large language models and continues to influence the direction of artificial intelligence research.